2025-10-30
vLLM and SGLang integration is ready! Check out the PR here.
2025-10-28
vLLM and SGLang integration will come soon!
vLLM and SGLang integration is ready! Check out the PR here.
vLLM and SGLang integration will come soon!
Modern LLMs are trained to 'think' primarily via explicit text generation, such as chain-of-thought, which defers reasoning to post-training and under-leverages pre-training data. We present Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens.
Through controlled experiments, we show this advantage stems not from increased knowledge storage, but from superior knowledge manipulation capabilities. We also show our latent reasoning is more faithful to the reasoning process than standard LLMs. Our resulting 1.4B and 2.6B models match the performance of up to 12B SOTA standard LLMs across a wide range of benchmarks, showing its potential as a scaling direction in a data-constrained era.
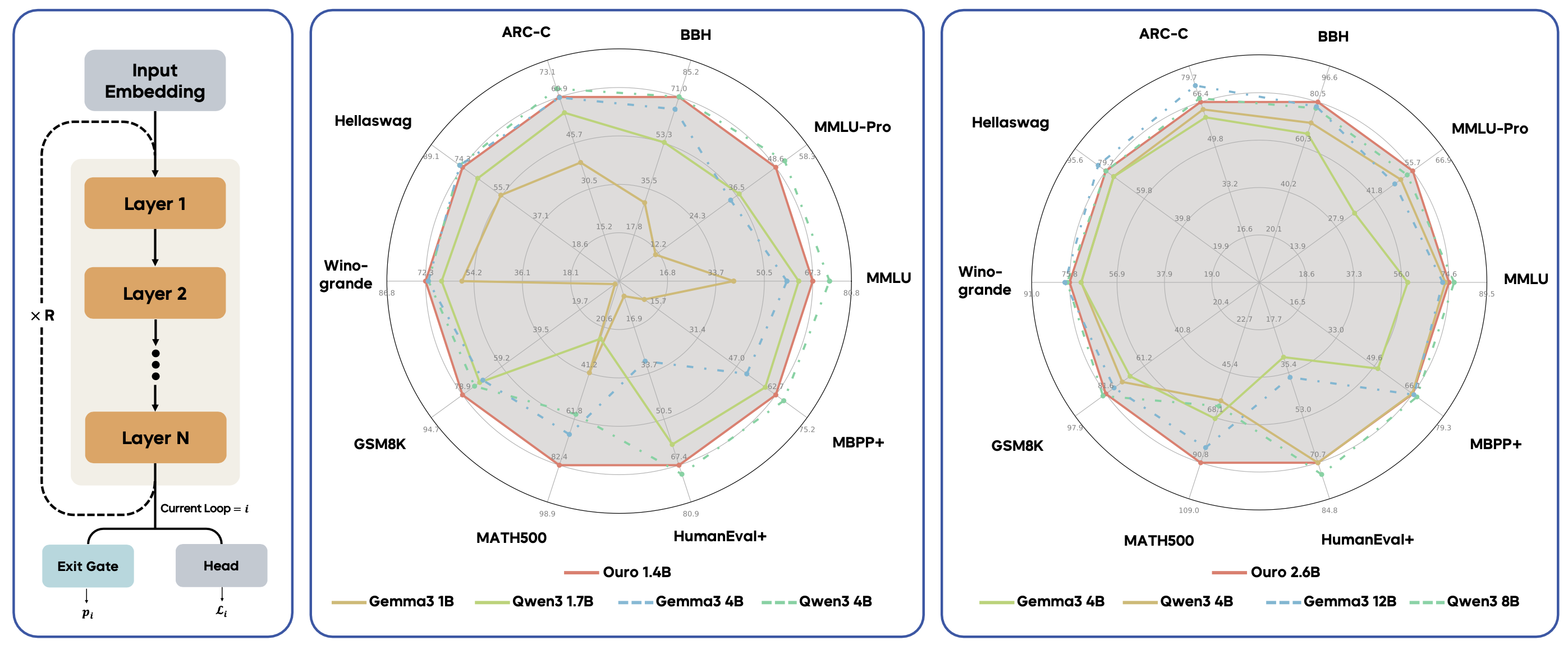
Ouro uses a parameter-shared looped architecture where the same transformer blocks are applied recurrently. This allows the model to perform iterative computation in latent space, enabling deeper reasoning without proportionally increasing parameter count. Our models use 4 recurrent steps (R4) to achieve exceptional parameter efficiency.
Through 7.7T token pre-training, our models demonstrate remarkable parameter efficiency:
Through controlled experiments on synthetic tasks, we demonstrate that the looped architecture's advantage stems not from increased knowledge storage, but from superior knowledge manipulation capabilities on tasks requiring fact composition and multi-hop reasoning.
We develop a novel training objective with entropy regularization that enables dynamic depth allocation. Simple inputs can exit after fewer recurrent steps, while complex problems automatically allocate more iterations, matching computational depth to input difficulty.
Our training pipeline is a carefully designed multi-stage process totaling 7.7T tokens of training data:
The architecture uses standard decoder-only Transformer with Rotary Position Embeddings (RoPE), SwiGLU activation, and sandwich normalization for enhanced training stability with deep recurrent computation.